From crash simulations to surrogate models
Even though digital simulations are widespread, each run — whether for crash testing or airflow analysis — is costly and limited in number. Strict confidentiality between car manufacturers also means valuable data is often locked away in silos, preventing reuse and collaboration.
To address these constraints, it is essential to maximize the value of existing simulations. One promising approach is the use of surrogate models: fast, lightweight stand-ins that estimate the behavior of high-fidelity simulations using previously generated data. These models can significantly reduce the time and resources required to explore new design configurations.
This article sums up the work presented at SIA Simulation Numérique 2025 [1]. It compares two surrogate modeling methods applied to crash test data from a benchmark provided by SIA, Renault and Stellantis [2].
- ReCUR: a reduced-order modeling technique that builds compact, fast, and accurate surrogate models from existing high-fidelity data. It is non-intrusive –no direct access to finite element solvers is needed — making it easy to integrate into engineering workflows.[3]
- Neural Fields: an advanced ML approach that also learns from existing simulations to create fast, accurate estimations.[4]
Both approaches use the same inputs and produce comparable outputs, allowing for a fair comparison.
We will also explore how transforming and preparing data properly can significantly boost model accuracy. This underlines a key insight: the engineer’s expertise and understanding of their data are just as important as the surrogate modeling method itself.
This work follows earlier efforts advocating a data-focused mindset in industrial companies, as outlined in our article: Overcoming key barriers to AI adoption in engineering simulation
Simulation data should indeed be recognized as a valuable asset rather than byproduct. Effectively managing this data enables the training of machine learning models that become increasingly powerful as data volumes grow, while still delivering meaningful insights even in low-data scenarios.
The crash simulation database
The dataset consists of 60 crash simulations of a structure representing a vehicle’s front. In these tests, variations are created by changing the thickness of six structural crash boxes.
— Example simulation of the structural dynamics
By virtually testing many different configurations, engineers can identify the designs offering the best trade-off between crash protection and structural weight. When automated, this process becomes an optimization study, where the system intelligently explores a wide range of possible designs to find the one that performs best based on safety and other key criteria. Virtual testing not only accelerates development but also ensures that every decision is backed by solid data, helping engineers design safer vehicles.
Exploring the parametric domain
The 60 parametric configurations are displayed on the following scatter plot:
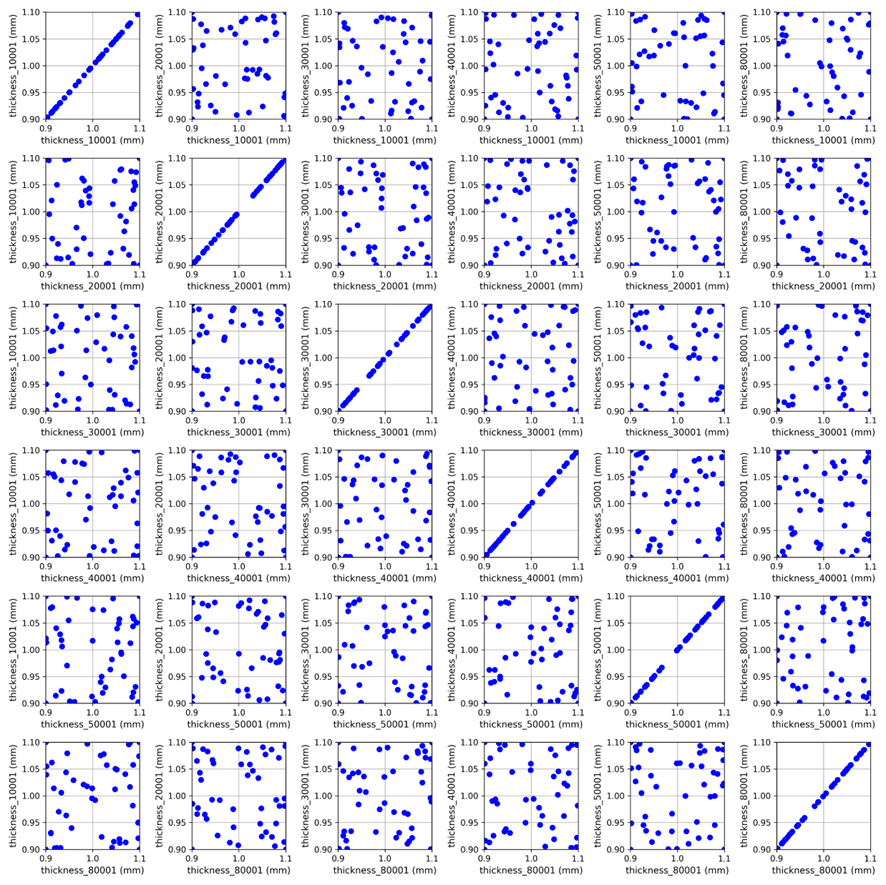
— Scatter plot of the parametric domain (each point represents a configuration).
The domain is well covered, with no strong correlations between input parameters. Miura’s tools make it easy to analyze such domains efficiently and, if needed, to explore specific solutions in greater detail using visualization solutions like ParaView.
In that database, the number of simulations available is ten times the number of design parameters, a common benchmark for optimization studies. One of the key challenges is to build a surrogate model with only a limited number of high-fidelity simulations. Then we propose to evaluate the accuracy according to the number of training simulations used, in order to assess whether the surrogate is reliable enough to support full optimization workflows.
From simulation to smart design: a streamlined workflow
The workflow starts with data transformation: turning complex simulation outputs into a format suitable for machine learning.
We then train fast, surrogate models using tools like Keras and TensorFlow.
Once trained, the models can be deployed in real-time through a ParaView plug-in, enabling engineers to interact directly with predictions, explore design alternatives, and even couple the model with optimization algorithms to automatically search for the best design based on key performance indicators (KPIs) like safety or efficiency.
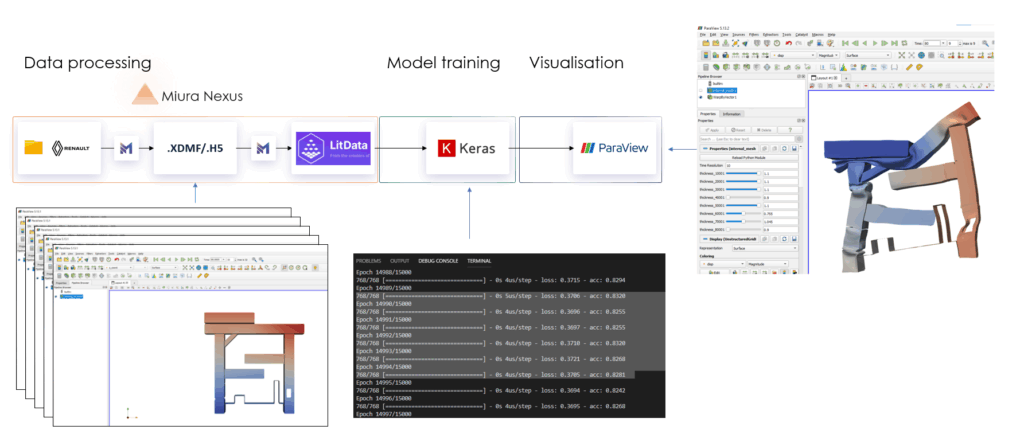
Miura Nexus platform connects and automates these steps. It unifies data across high-fidelity solvers, overcomes the limitations of proprietary formats, and applies observability principles to give teams full ownership of their simulation data. This foundation simplifies workflows and paves the way for adoption of scalable AI in engineering.
The substitution models
Two surrogate models were trained, one with the ReCUR reduced order modeling technique and another using neural field approach. Both were designed to minimize the error between estimations and high-fidelity reference data.
- ReCUR model: built on a reduced-order basis from CUR decomposition, with regression handled by a neural network. In this method, predictions are constrained to the space given by the bases directly built using high-fidelity data.
- Neural field model: directly maps configuration parameters (thicknesses), time steps and mesh nodes to displacement outputs.
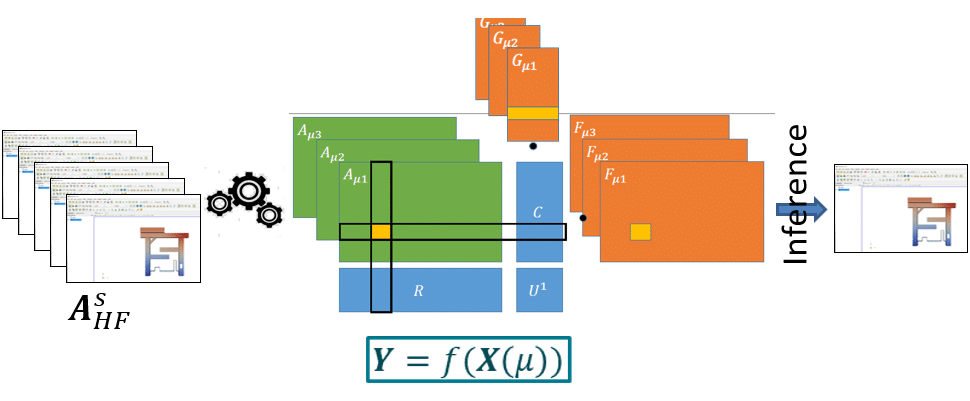
— Principle schema of the ReCUR method
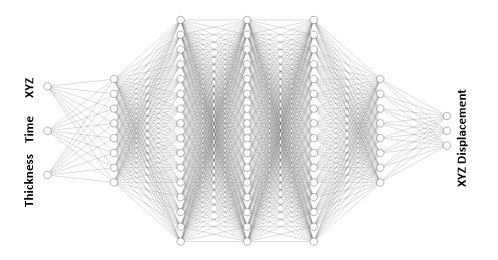
— Typical architecture of a Neural Field Network
Smarter modeling through expert-driven data transformation
Initial results with a single Neural Field were unsatisfactory, especially in areas of large deformation or rigid-body motion. Such areas are highlighted in the red circles on the subsequent figure.
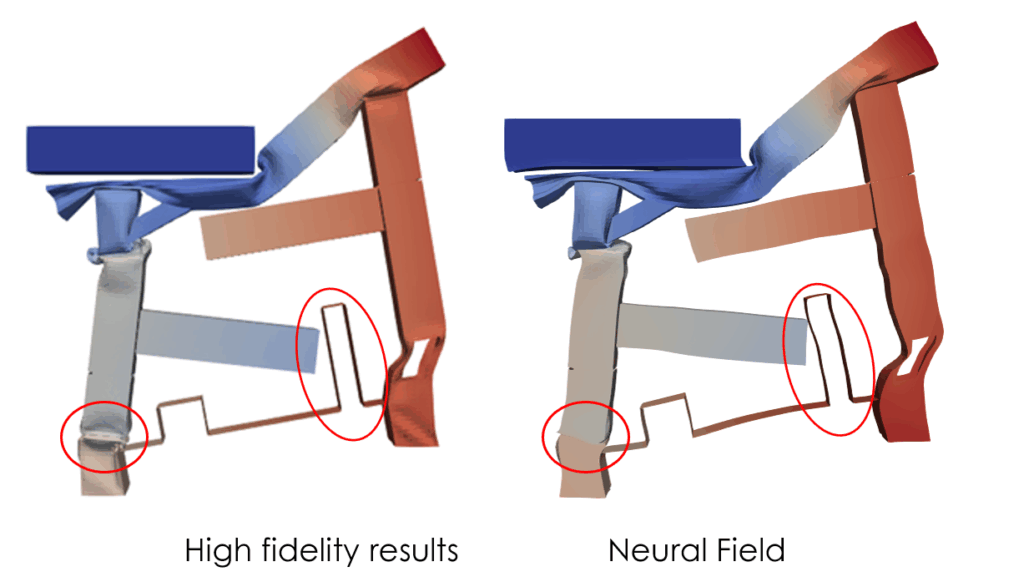
— Comparison between high-fidelity results and one single Neural Field estimates.
To improve accuracy, the displacement data was split into two components: one global that captures the overall movement of the structure (called rigid body motion), and another local that captures the local deformations during impact.
We then trained two separate neural field models, one for each component. This split allows each model to focus on a specific scale: global for rigid body motion, and local for deformation. The result is a much more accurate and reliable surrogate model.
This approach highlights how critical data transformation is in building effective machine learning models. It also shows the value of involving human experts in the process — because understanding the physics behind the data is key to make smart choices that machines alone can’t infer. Keeping humans “in the loop” leads to better, faster, and more trustworthy models.
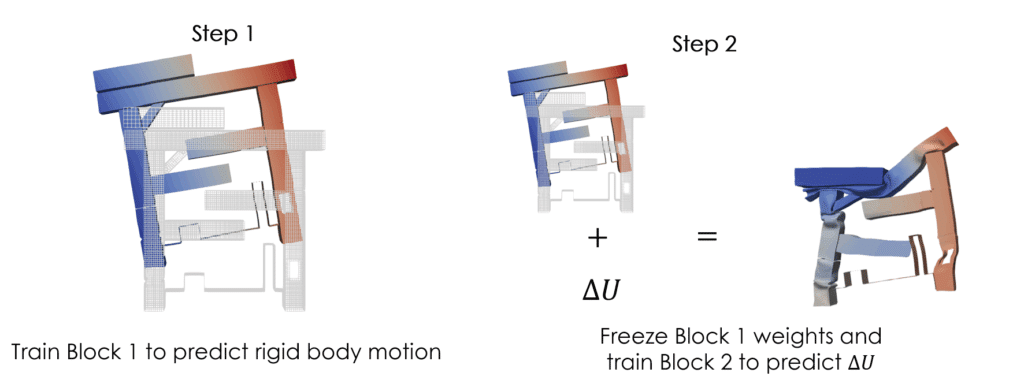
— Traning strategy for the two steps neural field
At Miura, we developed Nexus to make the implementation, testing, and deployment of data transformations seamless and efficient. Built on a ‘pipeline-as-code’ philosophy, Nexus enables rapid prototyping on local datasets and scalable deployment across entire simulation datasets. In doing so, it bridges the gap between the worlds of simulation and machine learning.
Be among the first to explore Nexus, test new capabilities, and shape its roadmap.
Join our Pioneers Program
Results
The subsequent figure compares the neural field approach without data transformation (on the left) and with the data transformation (on the right). The high-fidelity results are represented in light grey. This comparison demonstrates the improvements in the large deformation region and for the rigid body parts, indicating that the surrogate model better captures the physical behavior of the structure.
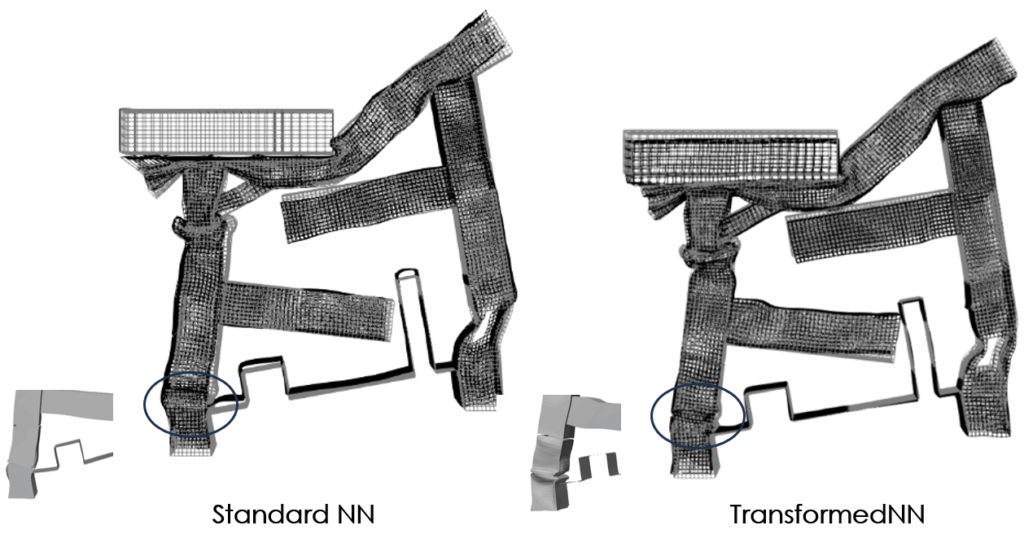
— Comparison of the estimates using single neural field (on the left) and two steps approach (on the right). High-fidelity displayed in light grey.
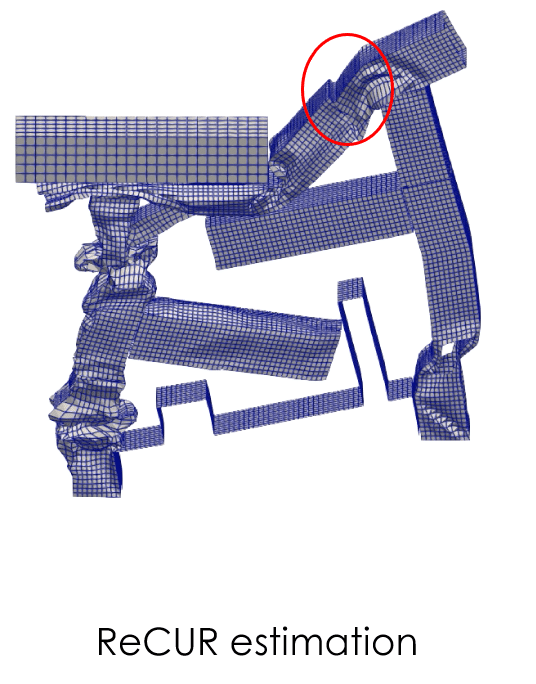
The estimation from the ReCUR model is shown below. The accuracy is satisfactory although some remain, notably in the red-circled region where a discontinuity in the mesh appears. Note that the data transformation was not applied to that surrogate model.
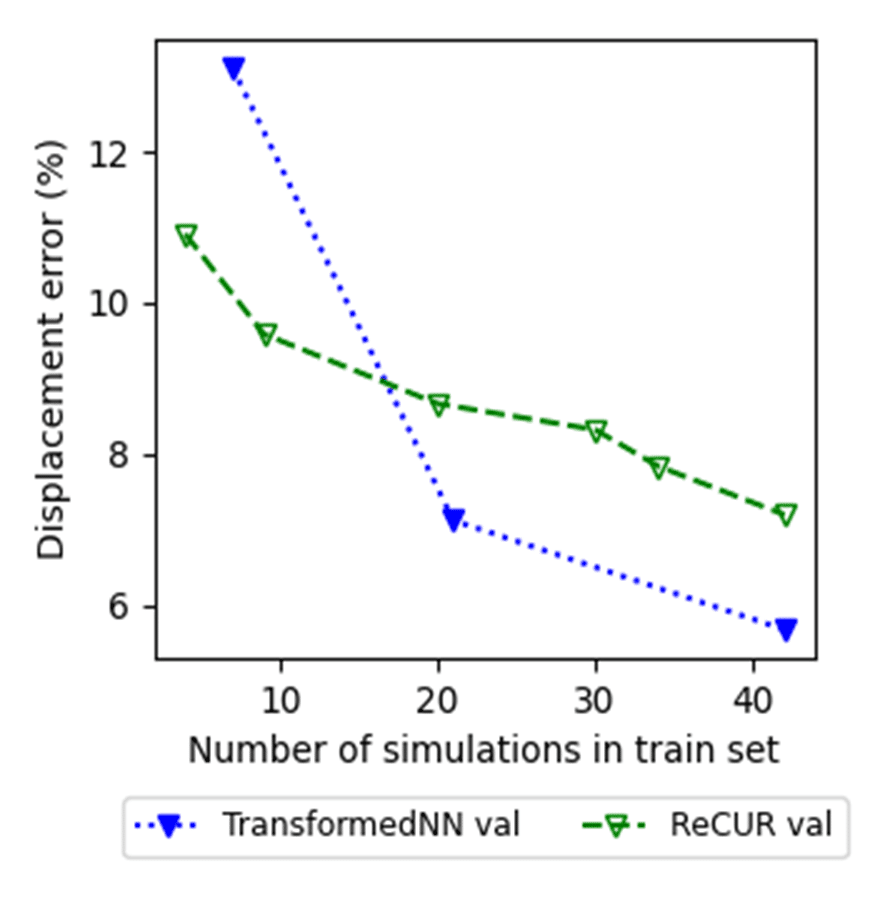
The two approaches are compared by computing the global error between the estimation results and the high-fidelity simulation. This error is tracked across all computations relative to the database size.
It shows that the ReCUR model performs better when the number of training computations is low, while the neural field becomes more precise when the training set contains more than 20 computations.
The ReCUR model trained on 40 computations required in 5 hours, while the neural field model took 15 hours. The estimation time for the ReCUR model is about 10 seconds, compared to under one second for the neural field model.
Note that optimization tasks can be effectively performed using the surrogate model built with only 20 high-fidelity simulations. The error remains acceptable for this type of study, where obtaining a reliable ranking of technical solutions is more critical than achieving highly precise estimations. In contrast, solving the same optimization problem directly with the high-fidelity solver, even with an efficient optimization algorithm, would require approximately 60 high-fidelity simulations. Using a surrogate model trained on just 20 high-fidelity simulations therefore results in significant time savings.
Interactive use
Beyond optimization, surrogate models can also be embedded in interactive plug-ins. Engineers can interact with the models as they would with traditional high-fidelity simulations. They can visualize estimations for unexplored configurations on the fly and perform dedicated post-processing to extract KPIs. This interactivity tool makes surrogate models powerful tools for narrowing down promising design directions.
The video below demonstrates the use of the model in an interactive plug-in.
Conclusions
This work demonstrates that efficient surrogate models can be built from a limited number of crash simulations.
A key takeaway is the importance of transforming the data in a way that reflects the physical behavior –a step that dramatically improves model accuracy. It also reinforces a central principle: human expertise remains essential. By embedding domain knowledge into data preparation, engineers can guide machine learning tools toward better, faster, and more trustworthy results.
Machine learning techniques, supported by Miura’s Nexus platform, offer industrial companies a way to take control and ownership of their simulation data. This capability is already proving valuable not only in automotive crash testing but also in aerospace, as demonstrated in our collaboration with CNES on antenna placement optimization.
🔗 Read our articles about how the collaboration with CNES is a step forward to integrate AI simulation in the space industry.
These examples show the versatility of the technology and its ability to support engineers across diverse industrial sectors.
Looking forward, this work opens the door to geometric deep learning—a powerful approach that can handle not just parametric variations, but also geometric and structural changes. This will be especially valuable in early-stage vehicle development, where exploring many design concepts quickly is critical.
[1] : T. Defoort, Y. Le Guennec, J. V. Aguado, D. Borzacchiello. Comparing traditional surrogate modelling and neural fields for vehicle crash simulation data. SIA Simulation numérique 2025, SIA, Apr 2025, Guyancourt (78), France.
https://hal.science/hal-05097364/
[2] : SIA Simulation numérique : challenge réduction de modèle :
https://www.sia.fr/evenements/371-challenge-reduction-modele?lng=en
[3] : Y. Le Guennec, J. P. Brunet, F. Z. Daim, M. Chau, Y. Tourbier: A parametric and non-intrusive reduced order model of car crash simulation. Computer Methods in Applied Mechanics and Engineering, 338, 2018.
https://hal.science/hal-01485276/document
[4] : Y. Xie et al.: Neural Fields in Visual Computing and Beyond, Computer Graphics Forum, 41, 2, 2022.
https://arxiv.org/abs/2111.11426