De la simulation de crash aux modèles de substitution
Même si les simulations numériques sont répandues, chaque exécution (qu’il s’agisse d’un test de crash ou d’une analyse d’écoulement) est coûteuse et limitée en nombre. La confidentialité stricte entre constructeurs automobiles signifie aussi que les données précieuses sont souvent enfermées dans des silos, empêchant leur réutilisation et la collaboration.
Pour faire face à ces contraintes, il est essentiel de maximiser la valeur des simulations existantes. Une approche prometteuse consiste à utiliser des modèles de substitution : des approximations rapides et légères qui estiment le comportement de simulations haute fidélité en s’appuyant sur des données déjà générées. Ces modèles peuvent réduire de manière significative le temps et les ressources nécessaires pour explorer de nouvelles configurations de design.
Cet article résume le travail présenté à SIA Simulation Numérique 2025 [1]. Il compare deux méthodes de modélisation de substitution appliquées à des données de crash fournies par un benchmark impliquant SIA, Renault and Stellantis [2].
- ReCUR : technique de modélisation réduite qui construit des modèles de substitution compacts, rapides et précis à partir de données haute fidélité existantes. Elle est non intrusive (aucun accès direct aux solveurs éléments finis n’est nécessaire) ce qui facilite l’intégration dans les workflows d’ingénierie.[3]
- Neural Fields : approche avancée de machine learning qui apprend aussi à partir de simulations existantes pour créer des estimations rapides et précises.[4]
Les deux approches utilisent les mêmes entrées et produisent des sorties comparables, ce qui permet une comparaison équitable.
Nous explorons aussi comment transformer et préparer correctement les données peut améliorer significativement la précision des modèles. Cela souligne une idée clé : l’expertise de l’ingénieur et sa compréhension des données sont tout aussi importantes que la méthode de modélisation elle-même.
Ce travail fait suite à des initiatives précédentes promouvant une approche axée sur les données dans les entreprises industrielles, comme présenté dans notre article : surmonter les principaux freins à l’adoption de l’intelligence artificielle en simulation numérique.
Les données de simulation doivent en effet être reconnues comme un actif précieux plutôt que comme un sous-produit. Une gestion efficace de ces données permet d’entraîner des modèles de machine learning qui deviennent de plus en plus performants à mesure que le volume de données augmente, tout en fournissant des insights pertinents même dans des situations avec peu de données.
La base de données de simulation de crash
La base de données se compose de 60 simulations de crash d’une structure représentant l’avant d’un véhicule. Dans ces tests, les variations sont créées en changeant l’épaisseur de six zones structurelles de crash.
— Exemple de simulation de dynamique structurelle
En testant virtuellement de nombreuses configurations différentes, les ingénieurs peuvent identifier les designs offrant le meilleur compromis entre protection en cas de choc et poids structurel. Quand ce processus est automatisé, il devient une étude d’optimisation où le système explore intelligemment une large gamme de designs possibles pour trouver celui qui fonctionne le mieux selon des critères de sécurité et d’autres indicateurs clés. Les tests virtuels accélèrent non seulement le développement, mais assurent aussi que chaque décision repose sur des données solides, aidant les ingénieurs à concevoir des véhicules plus sûrs.
Exploration du domaine paramétrique
Les 60 configurations paramétriques sont affichées sur un nuage de points :
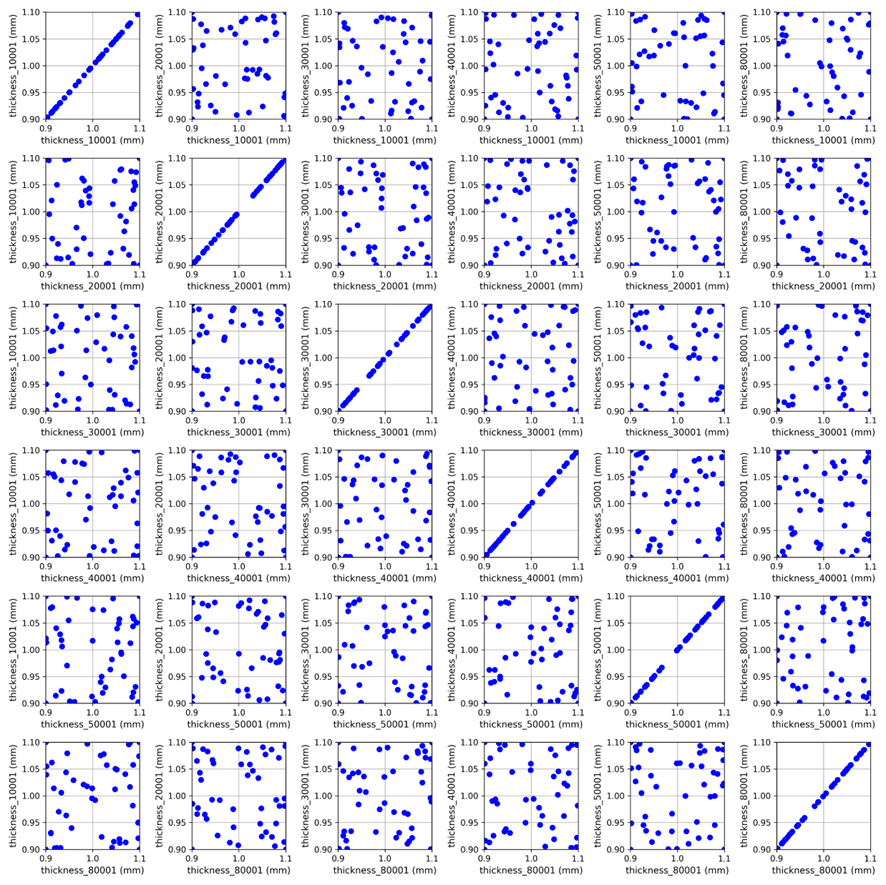
— Nuage de points du domaine paramétrique (chaque point représente une configuration).
Le domaine est bien couvert, sans fortes corrélations entre les paramètres d’entrée. Les outils de Miura facilitent l’analyse de tels domaines de manière efficace et, si nécessaire, l’exploration de solutions spécifiques en détail à l’aide de solutions de visualisation comme ParaView.
Dans cette base de données, le nombre de simulations disponibles est dix fois supérieur au nombre de paramètres de conception, un repère courant pour des études d’optimisation. Un des défis clés est de construire un modèle de substitution avec seulement un petit nombre de simulations haute fidélité. Nous proposons ensuite d’évaluer la précision selon le nombre de simulations d’entraînement utilisées, afin d’estimer si le modèle de substitution est suffisamment fiable pour supporter des workflows complets d’optimisation.
Du traitement des simulations à la conception intelligente : un workflow simplifié
Le workflow commence par la transformation des données : convertir des sorties de simulation complexes en un format adapté au machine learning.
Ensuite, on entraîne des modèles de substitution rapides en utilisant des outils comme Keras et TensorFlow.
Une fois entraînés, ces modèles peuvent être déployés en temps réel via un plug-in ParaView, permettant aux ingénieurs d’interagir directement avec les prédictions, d’explorer des alternatives de design et même de coupler le modèle avec des algorithmes d’optimisation pour rechercher automatiquement le meilleur design selon des indicateurs de performance clés (KPIs) tels que la sécurité ou l’efficacité.
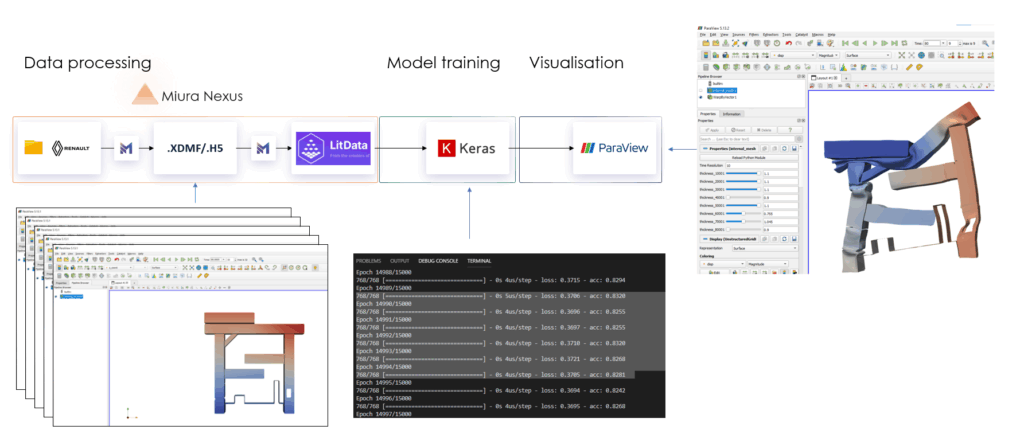
La plateforme Miura Nexus relie et automatise ces étapes. Elle unifie les données à travers les solveurs haute fidélité, dépasse les limitations des formats propriétaires et applique des principes d’observabilité pour donner aux équipes la pleine propriété de leurs données de simulation. Cette base simplifie les workflows et ouvre la voie à l’adoption d’une IA industrialisable en ingénierie.
Les modèles de substitution
Deux modèles de substitution ont été entraînés : l’un avec la méthode de modélisation réduite ReCUR et l’autre en utilisant l’approche Neural Field. Les deux visent à minimiser l’erreur entre les estimations et les données de référence haute fidélité.
- Modèle ReCUR :construit sur une base d’ordre réduit via la décomposition CUR, avec la régression gérée par un réseau neuronal. Dans cette méthode, les prédictions sont contraintes à l’espace défini par les bases construites directement à partir des données haute fidélité.
- Modèle Neural Field : associe directement les paramètres de configuration (Thickness), les pas de temps et les nœuds du maillage pour prédire les déplacements.
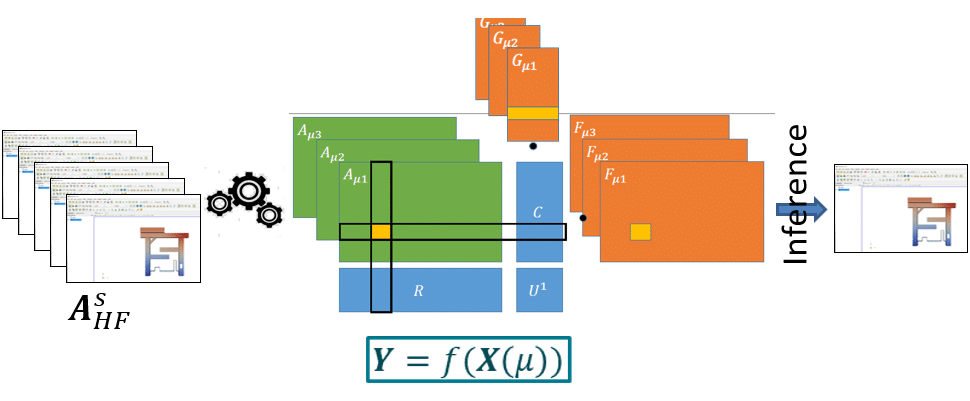
— Schéma de principe de la méthode ReCUR
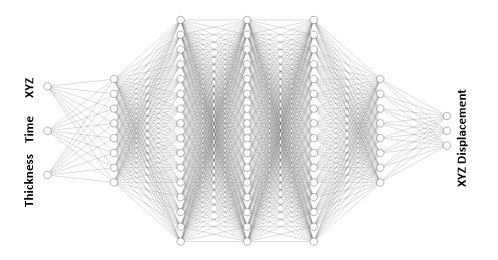
— Architecture typique d’un réseau Neural Field
Modélisation plus intelligente via la transformation des données
Les résultats initiaux avec un seul modèle Neural Field étaient insatisfaisants, notamment dans les zones de grande déformation ou de mouvement de corps rigide, indiquées par des cercles rouges sur la figure suivante.
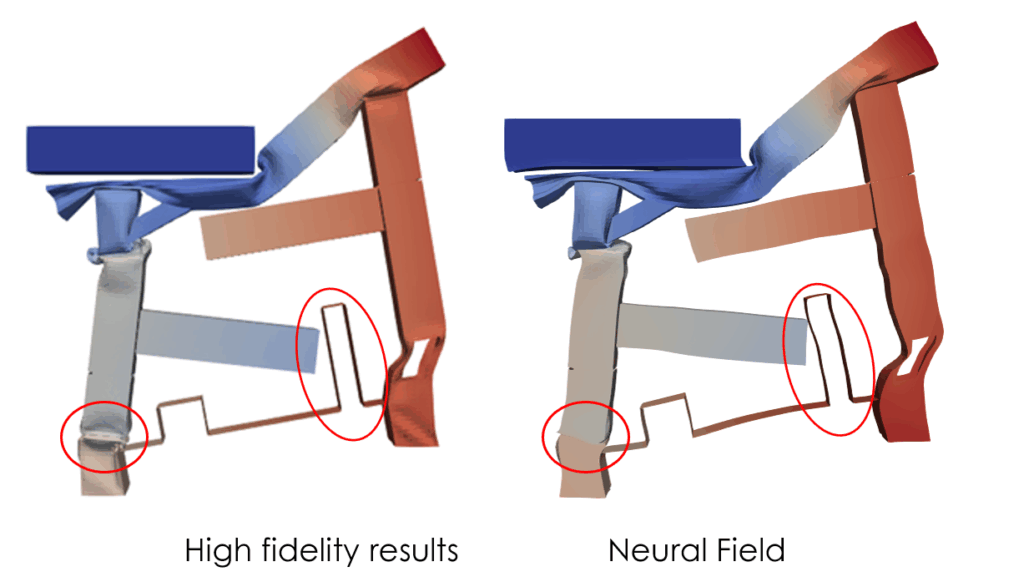
—Comparaison entre les résultats haute fidélité et les estimations d’un seul Neural Field.
Pour améliorer la précision, les données de déplacements ont été divisées en deux composantes : une composante globale qui capture le mouvement global de la structure (appelée rigid body motion) et une composante locale qui capture les déformations locales pendant l’impact.
Nous avons ensuite entraîné deux modèles Neural Field séparés, un pour chaque composante. Cette séparation permet à chaque modèle de se concentrer sur une échelle spécifique : global pour le mouvement de corps rigide, et local pour la déformation. Résultat : un modèle de substitution beaucoup plus précis et fiable.
Cette approche met en évidence à quel point la transformation des données est critique pour construire des modèles de machine learning efficaces. Elle montre aussi la valeur de l’implication d’experts humains dans le processus — comprendre la physique derrière les données est essentiel pour faire des choix intelligents que les machines seules ne peuvent pas deviner. Garder l’humain “dans la boucle” conduit à des modèles plus fiables, plus rapides et plus dignes de confiance
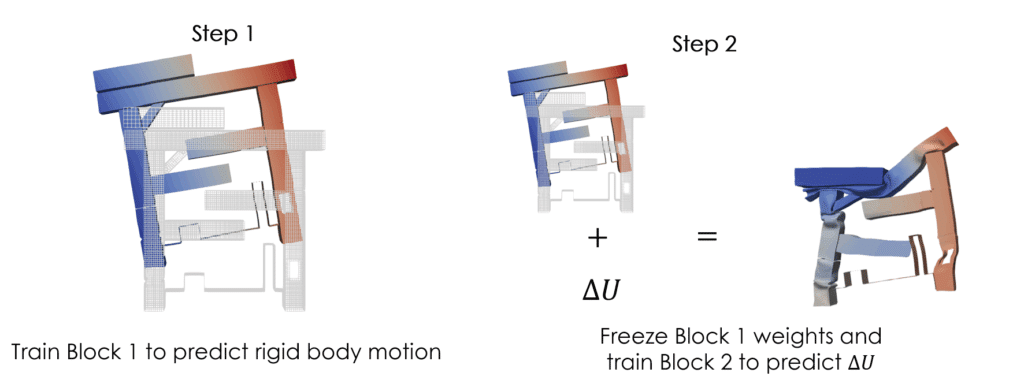
— Stratégie d’entraînement pour le Neural Field en deux étapes
Chez Miura, nous avons développé Nexus pour rendre l’implémentation, les tests et le déploiement des transformations de données fluides et efficaces. Conçu sur une philosophie « pipeline-as-code », Nexus permet des prototypes rapides sur des jeux de données locaux et un déploiement scalable à travers des ensembles de données de simulation complets. Ainsi, il comble le fossé entre les mondes de la simulation et du machine learning.
Soyez parmi les premiers à explorer Nexus et à tester ses nouvelles fonctionnalités.
Rejoignez notre programme Nexus Pioneers
Resultats
La figure suivante compare l’approche Neural Field sans transformation de données (à gauche) et avec la transformation de données (à droite). Les résultats haute fidélité sont représentés en gris clair. Cette comparaison montre des améliorations dans la région de grande déformation et pour les parties de corps rigide, indiquant que le modèle de substitution capture mieux le comportement physique de la structure.
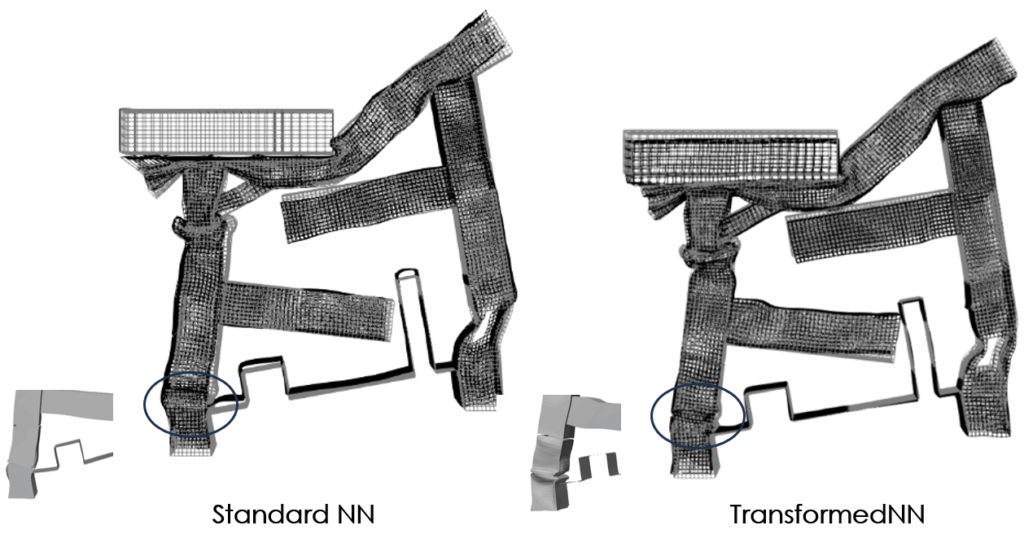
— Comparaison des estimations avec un seul Neural Field (à gauche) et approche en deux étapes (à droite). Haute fidélité affichée en gris clair.
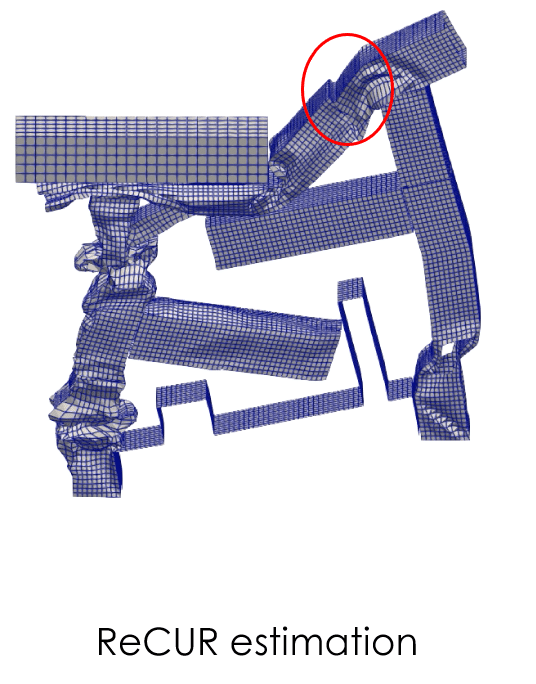
L’estimation du modèle ReCUR est montrée ci-dessous. La précision est satisfaisante bien que certains écarts subsistent, notamment dans la région entourée en rouge où une discontinuité du maillage apparaît. Notez que la transformation des données n’a pas été appliquée à ce modèle de substitution.
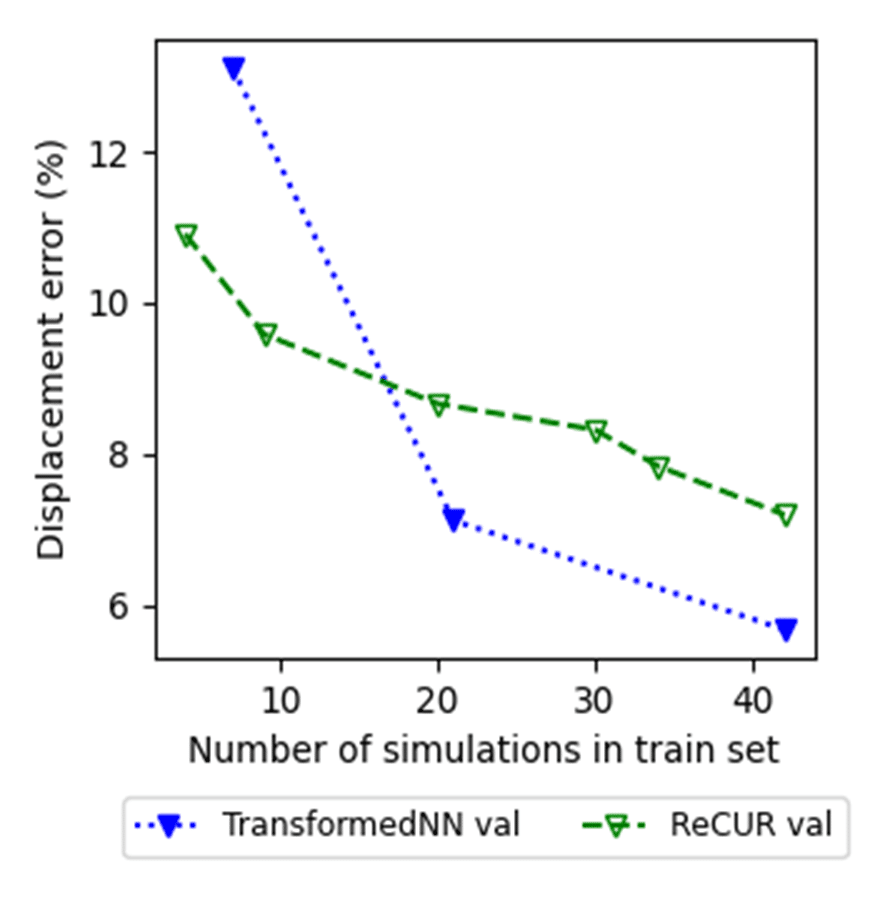
Les deux approches sont comparées en calculant l’erreur globale entre les résultats estimés et la simulation haute fidélité. Cette erreur est suivie à travers toutes les simulations en fonction de la taille de la base de données.
On observe que le modèle ReCUR performe mieux lorsque le nombre de simulations d’entraînement est faible, tandis que le Neural Field devient plus précis lorsque l’ensemble d’entraînement contient plus de 20 simulations.
Le modèle ReCUR entraîné sur 40 simulations a requis environ 5 heures, tandis que le modèle Neural Field a pris 15 heures. Le temps d’estimation pour le modèle ReCUR est d’environ 10 secondes, contre moins d’une seconde pour le modèle Neural Field.
Notez que les tâches d’optimisation peuvent être effectuées efficacement en utilisant un modèle de substitution construit avec seulement 20 simulations haute fidélité. L’erreur reste acceptable pour ce type d’étude, où obtenir un classement fiable des solutions techniques est plus critique que d’obtenir des estimations très précises. En revanche, résoudre le même problème d’optimisation directement avec le solveur haute fidélité, même avec un algorithme d’optimisation efficace, nécessiterait environ 60 simulations haute fidélité. Utiliser un modèle de substitution entraîné sur seulement 20 simulations haute fidélité entraîne donc des économies de temps significatives.
Utilisation interactive
Au-delà de l’optimisation, les modèles de substitution peuvent aussi être intégrés dans des plug-ins interactifs. Les ingénieurs peuvent interagir avec eux comme ils le feraient avec des simulations haute fidélité traditionnelles. Ils peuvent visualiser les estimations pour des configurations non explorées à la volée et effectuer un post-traitement dédié pour extraire des indicateurs clés de performance. Cet outil interactif fait des modèles de substitution des outils puissants pour affiner rapidement les directions de conception prometteuses.
La vidéo associée montre l’utilisation du modèle dans un plug-in interactif.
Conclusions
Ce travail démontre que des modèles de substitution efficaces peuvent être construits à partir d’un nombre limité de simulations de crash.
Une prise essentielle est l’importance de transformer les données d’une manière qui reflète le comportement physique, une étape qui améliore considérablement la précision des modèles. Cela renforce aussi un principe central : l’expertise humaine reste essentielle. En incorporant la connaissance du domaine dans la préparation des données, les ingénieurs peuvent guider les outils de machine learning vers des résultats meilleurs, plus rapides et plus fiables.
Les techniques de machine learning, supportées par la plateforme Miura Nexus, offrent aux entreprises industrielles un moyen de prendre le contrôle et la propriété de leurs données de simulation. Cette capacité se révèle déjà précieuse non seulement dans les tests de crash automobiles, mais aussi dans l’aérospatial, comme démontré dans la collaboration avec CNES sur l’optimisation du placement d’antennes.
🔗 Lisez notre article Comment la collaboration avec le CNES constitue un pas en avant pour intégrer l’IA dans la simulation numérique spatiale.
Ces exemples montrent la polyvalence de la technologie et sa capacité à soutenir les ingénieurs dans divers secteurs industriels.
Ce travail ouvre la porte au Geometric Deep Learning: une approche puissante capable de gérer non seulement des variations paramétriques, mais aussi des changements géométriques et structurels. Cela sera particulièrement précieux dans les premières phases de développement de véhicules, où explorer de nombreux concepts de design rapidement est crucial.
[1] : T. Defoort, Y. Le Guennec, J. V. Aguado, D. Borzacchiello. Comparing traditional surrogate modelling and neural fields for vehicle crash simulation data. SIA Simulation numérique 2025, SIA, Apr 2025, Guyancourt (78), France.
https://hal.science/hal-05097364/
[2] : SIA Simulation numérique : challenge réduction de modèle :
https://www.sia.fr/evenements/371-challenge-reduction-modele?lng=en
[3] : Y. Le Guennec, J. P. Brunet, F. Z. Daim, M. Chau, Y. Tourbier: A parametric and non-intrusive reduced order model of car crash simulation. Computer Methods in Applied Mechanics and Engineering, 338, 2018.
https://hal.science/hal-01485276/document
[4] : Y. Xie et al.: Neural Fields in Visual Computing and Beyond, Computer Graphics Forum, 41, 2, 2022.
https://arxiv.org/abs/2111.11426